業務(wu)咨(zi)詢(xun)熱線:029-89194301
- 首頁
-
智慧交通
智慧交通MTI系列軟件
- 品質工程信息化管理平臺
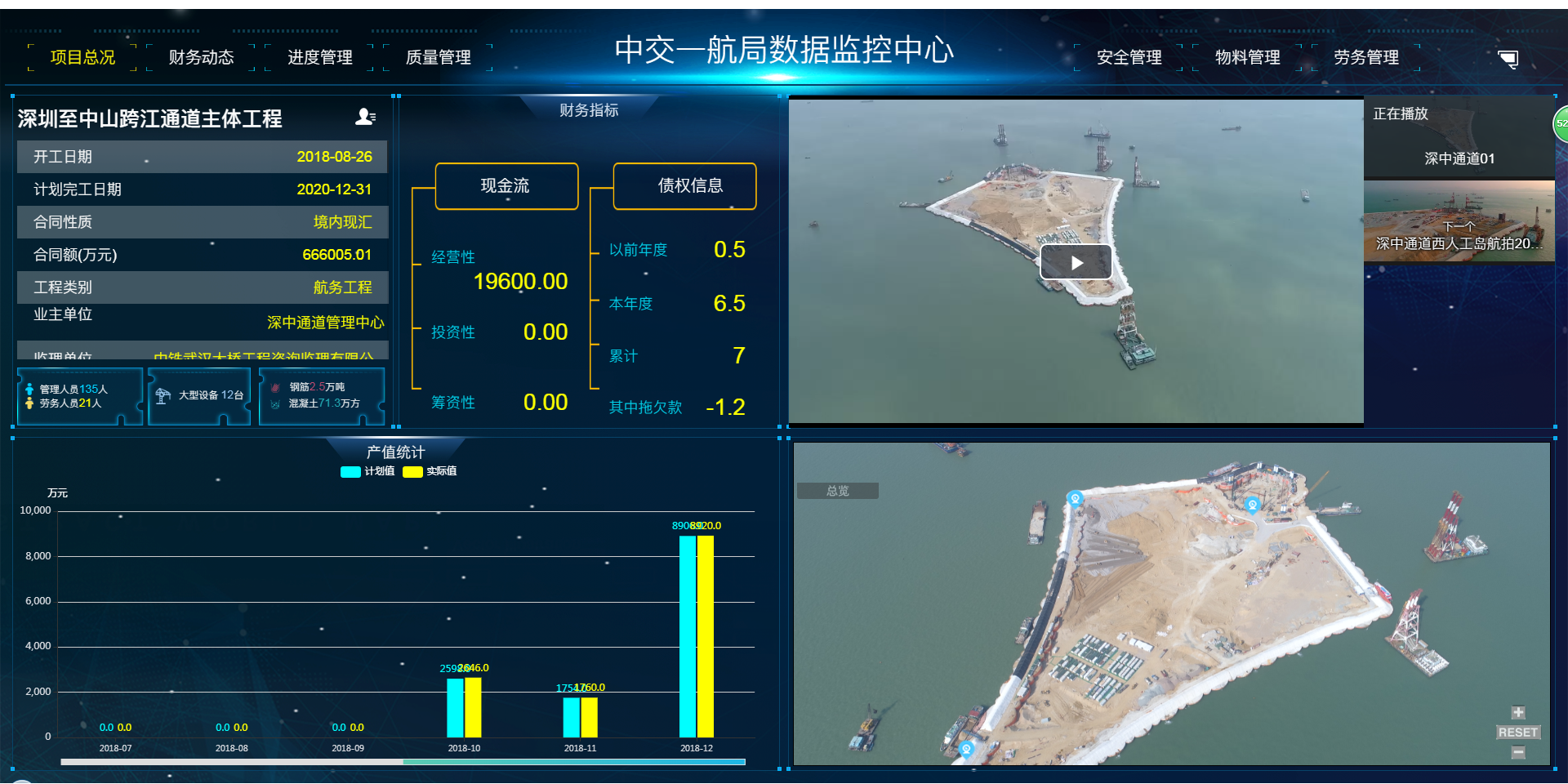
- BIM+GIS可視化工程管理平臺
- 生產管理會議系統
- 形象進度管理系統
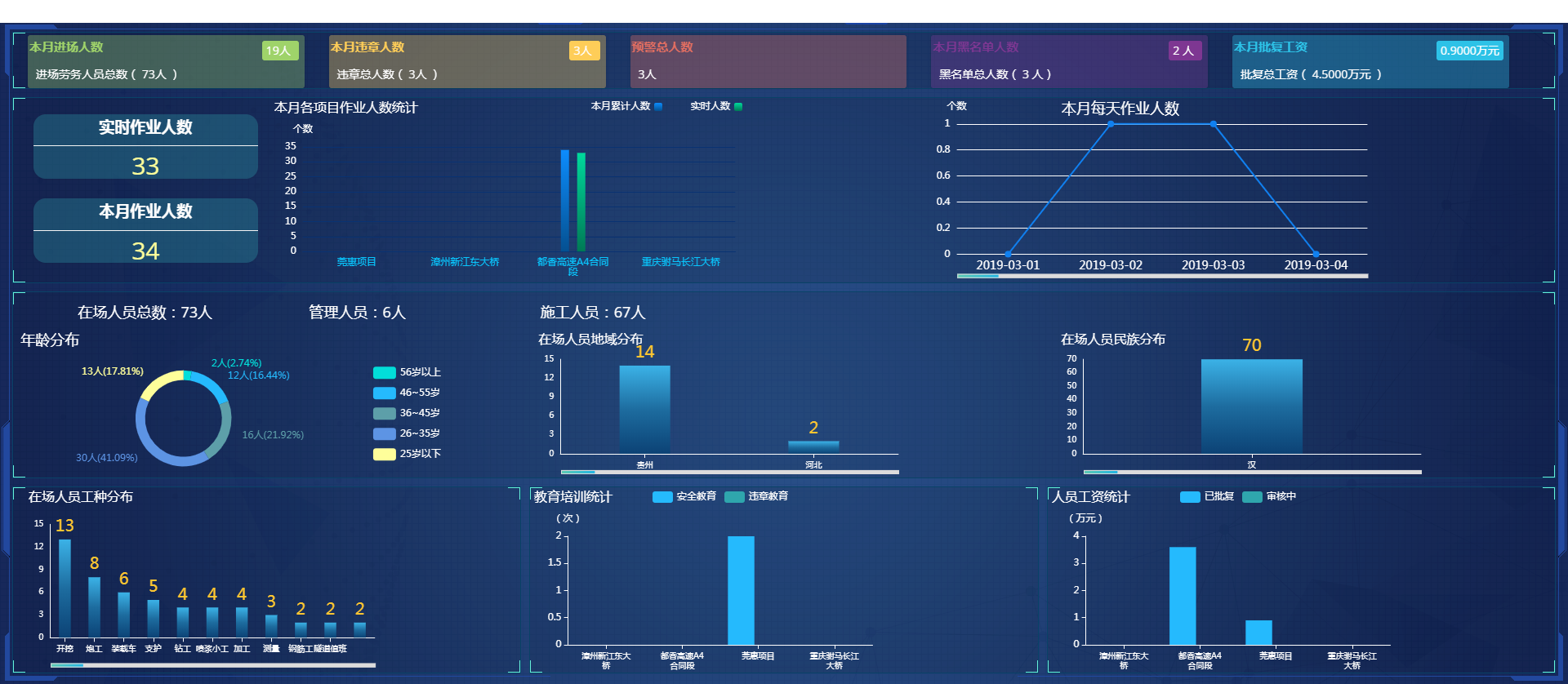
- 勞務人員實名制管理系統
- 智慧鋼筋加工廠數字孿生平臺
- 路基路面施工質量監測系統
- 無人機直播系統
- 物資管理系統
- 設備管理系統
- 梁場管理系統
- 邊坡監測預警系統
- 強夯監控系統
安全管理MTS系列軟件
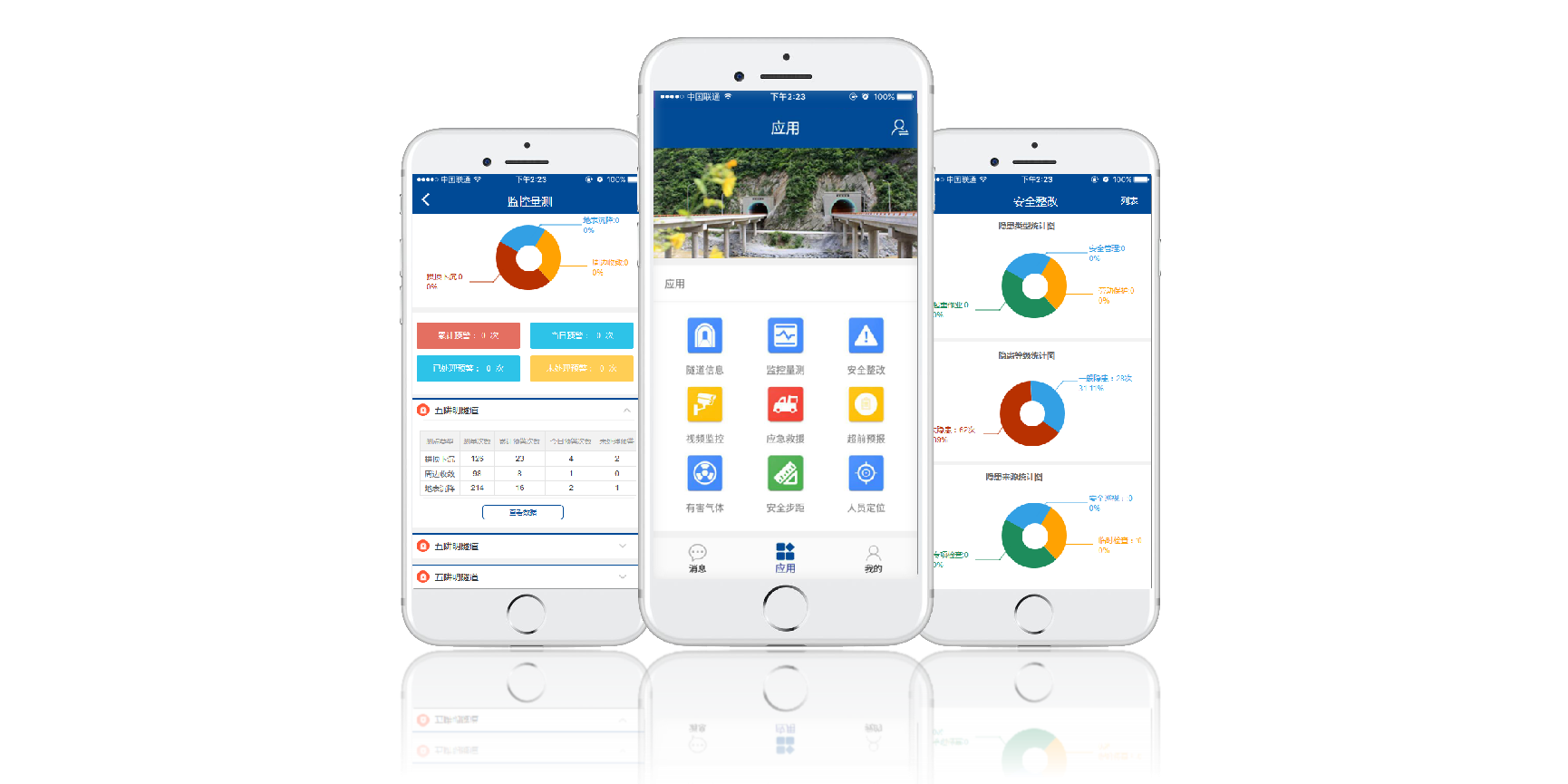
- 隧道氣體監測預警系統
- 隧道安全步距監測系統
- 隧道人員精確定位系統
- 隧道門禁系統(人車分離)
- 視頻監控AI預警系統
- 隧道監控量測預警系統
- 運輸車輛監測系統
- 塔吊安全監控預警系統
- 龍門吊安全監控預警系統
- 架橋機安全監控預警系統
- 邊坡安全監控預警系統
- 場站環境監測預警系統
- 試驗室溫濕度監控預警系統
質量管理MTQ系列軟件
- 拌合機聯網監測預警系統
- 試驗室設備監測預警系統
- 智能張拉監測預警系統
- 智能壓漿監測預警系統
- 路面攤鋪監控預警系統
- 路基壓實監測預警系統
- 強夯智能監控預警系統
- 榮譽資質
- 新聞動態
- 業務案例
- 關于我們